NVIDIA NeMo和triton区别:一文解析NeMo和triton的不同特点
更新时间:2023-12-25 18:33:27作者:xhjaty

1. NVIDIA NeMo(NVIDIA Neuronal Modules):
- NVIDIA NeMo是一个用于自然语言处理(NLP)任务的开源工具包,它提供了一系列经过预训练的语音和语言模型。以及用于构建和训练自定义语音和自然语言处理模型的工具和库。NeMo可以用于语音识别、语音合成、语言理解、自然语言生成等多种 NLP 任务。
- NVIDIA NeMo旨在为研究人员和开发者提供一个灵活且强大的工具包,用于构建和训练自定义的语音和自然语言处理模型,从而加速 NLP 技术的研究和应用。
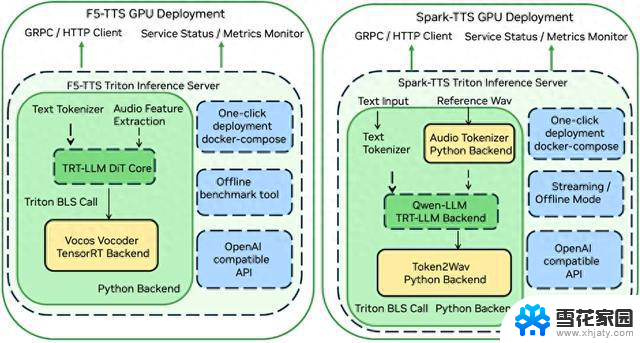
2. NVIDIA Triton Inference Server:
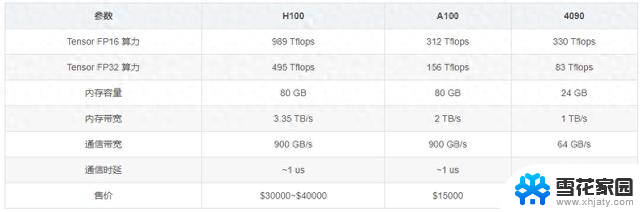
- NVIDIA Triton Inference Server是一个用于部署和推理深度学习模型的开源推理服务器。它支持多种深度学习框架(如TensorFlow、PyTorch、ONNX等),并提供了高性能的模型推理服务,可用于生产环境中的实时推理和批处理推理。
- Triton Inference Server可以用于构建端到端的深度学习推理管道,支持模型的加载、管理、批处理推理、动态批处理大小调整等功能。适用于各种推理场景,包括边缘推理、数据中心推理等。
因此,NVIDIA NeMo主要用于自然语言处理领域的模型开发和训练,而NVIDIA Triton Inference Server主要用于深度学习模型的部署和推理服务。这两个产品在不同阶段的深度学习应用中扮演着不同的角色,NeMo用于模型的构建和训练,而Triton用于模型的部署和推理。